구문 분석(Syntax analysis) 과정은 BNF에 기반하는데 이는 명확, 간결하고 paser의 기초가 되며 유지보수가 용이하다는 장점이 있기 때문이다.
구문 분석은 Lexical analyzer와 Syntax analzer(Parser) 두 가지 부분으로 구성된다. 이들이 분리되어 있는 이유는 다음과 같은 이유가 있다.
- 단순성(Simplicity) : 어휘 분석이 상대적으로 단순해서 분리 후 더 단순해질 수 있음
- 효율성(Efficiency) : 어휘 분석이 전체 컴파일 시간의 큰 부분을 차지하기 때문에 최적화가 필요하지만 구문 분석기는 최적화가 필요 없기 때문에 분리가 효과적
- 이식성(Portability) : 어휘 분석기는 파일 입력이 플랫폼에 종속적이지만 구문 분석기는 독립적이기 때문
Lexical analysis(어휘 분석)
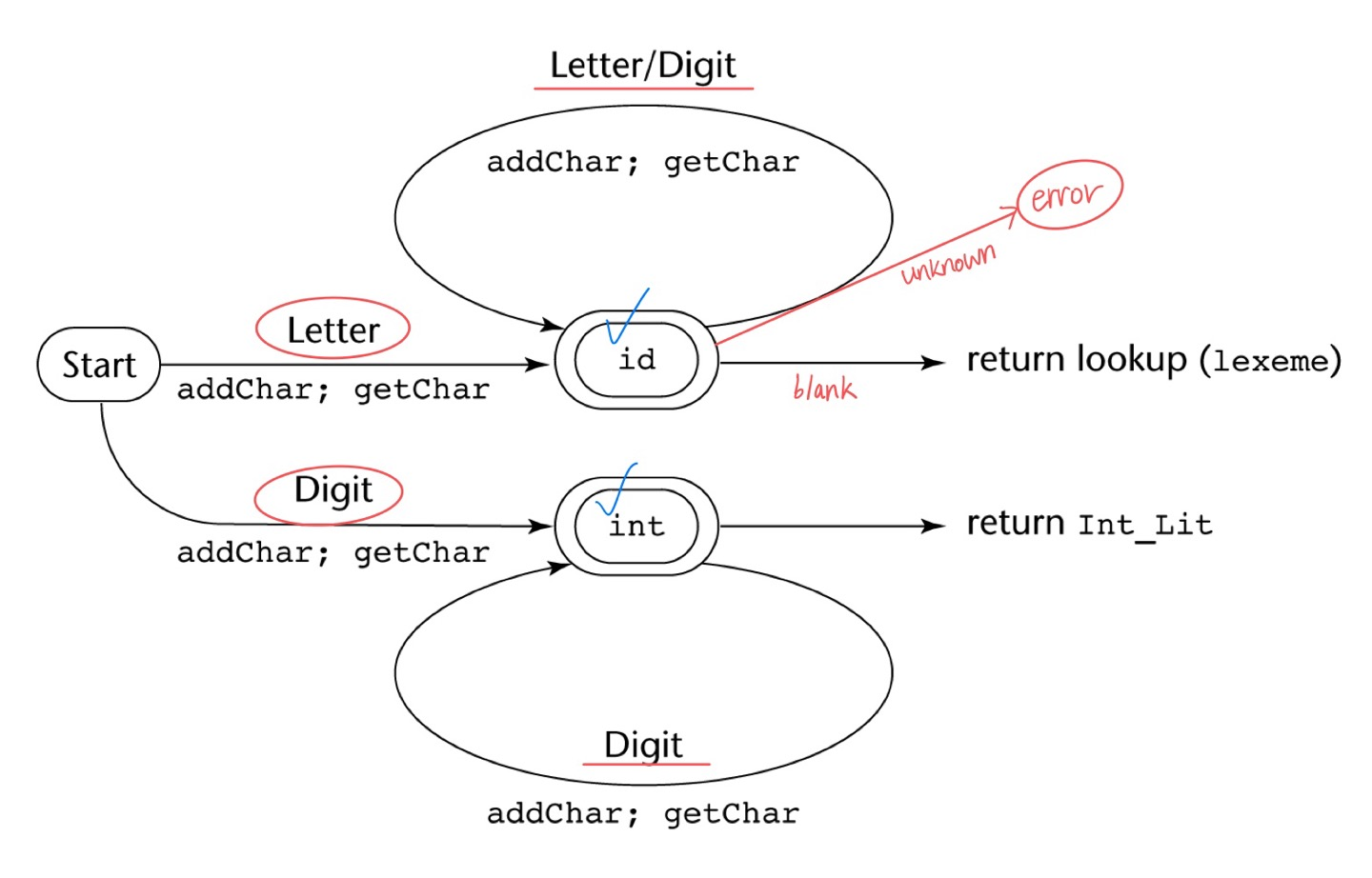
Lexical analyzer(어휘 분석기)는 일종의 패턴 매칭기로 문자들을 모아서 논리적인 단위로 그룹핑을하는데, 이들을 lexemes 또는 token이라고 한다. 이렇게 구분된 token들에 에러가 있는지 검사하고 또한 문자열에서 공백을 제거하기도 한다.
※ 어휘 분석기를 구성하는 방법 - State Diagram(상태 전이 다이어그램)
Syntax analysis(구문 분석)
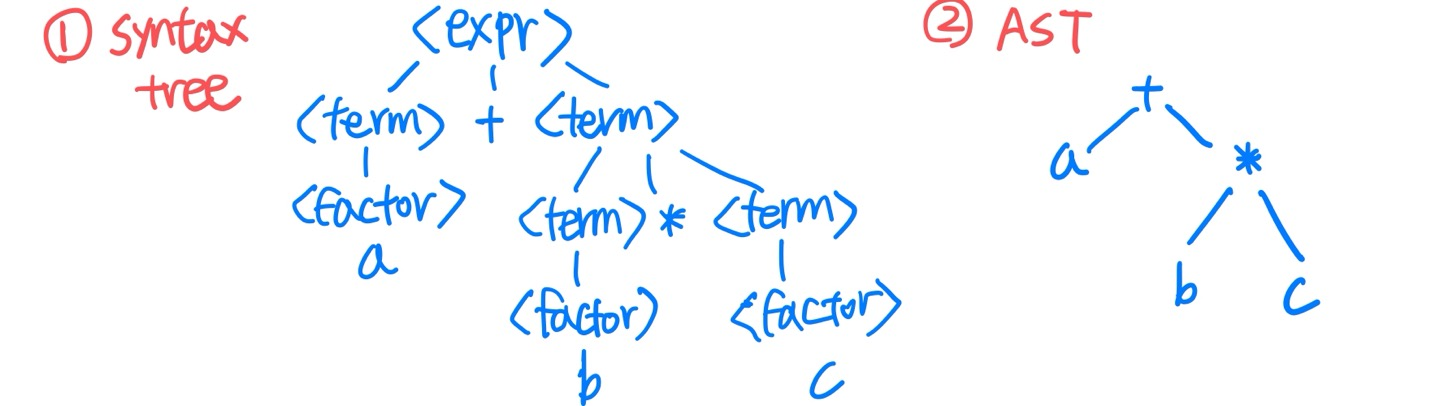
Syntax analysis는 파싱(Parsing)이라고도 하며 expression, statement, program unit 단위로 문법 검사를 하며 해당 입력의 AST(추상 구문 트리)를 생성하여 반환한다.

※ AST(추상 구문 트리)란?
- 입력 스트링의 구문 구조를 추상적으로 보여주는 트리
- 일반적인 Syntax tree(parse tree)에서 부가 정보를 제거한 tree
※ 파싱의 목적
- 모든 syntax error를 찾는 것
- AST를 생성하는 것
Parser의 종류
- Top-down Parser
- root부터 아래로 내려가면서 parse tree를 생성
- leftmost derivation을 기반으로함
- RD Parser와 LL Parser가 있음
- Left Recursion Problem이 존재함 - Bottom-up Parser
- leaf부터 root까지 올라가면서 parse tree를 생성
- rightmost derivation의 역순으로 진행됨
- LR Parser가 있음
- Top-down parser보다 더 좋은 성능을 보임
RD Parser(Recursive-Descent Parser)
- nonterminal 당 각각의 함수를 만들어서 이들을 재귀적으로 호출하며 parse tree를 생성하는 방식
- EBNF에 이상적으로 적합하다. (BNF보다 더 적은 nonterminal을 사용할 수 있기 때문)

RHS의 각각의 terminal symbol들에 대해서는 그 값들을 처리해주면 되고 nonterminal symbol들에 대해서는 각각의 함수를 호출함으로써 nonterminal symbol을 처리한다.
※ Top-down Parser의 문제점 1 - Left Recursion Problem
A -> Aa | ... 또는 A -> B B -> A 와 같은 문법들은 left recursion이 발생할 수 있다. 이러한 문장들은 Top-down parser로 구현이 불가능하다. 따라서 이런 경우 BNF 자체를 바꾸거나 Bottom-up parser로 구현해야 한다.

※ Top-down Parser의 문제점 2 - pairwise disjointness test을 실패하는 문법
각각의 nonterminal symbol에 대해서 RHS이 두 개 이상일 때, 가장 먼저 나오는 terminal이 서로 같아서는 안된다는 것이다. 가장 먼저 나오는 terminal이 같은 경우 Top-down parser로 구현이 불가능하다. 이런 경우 Left facotring을 통해서 해결할 수 있다.
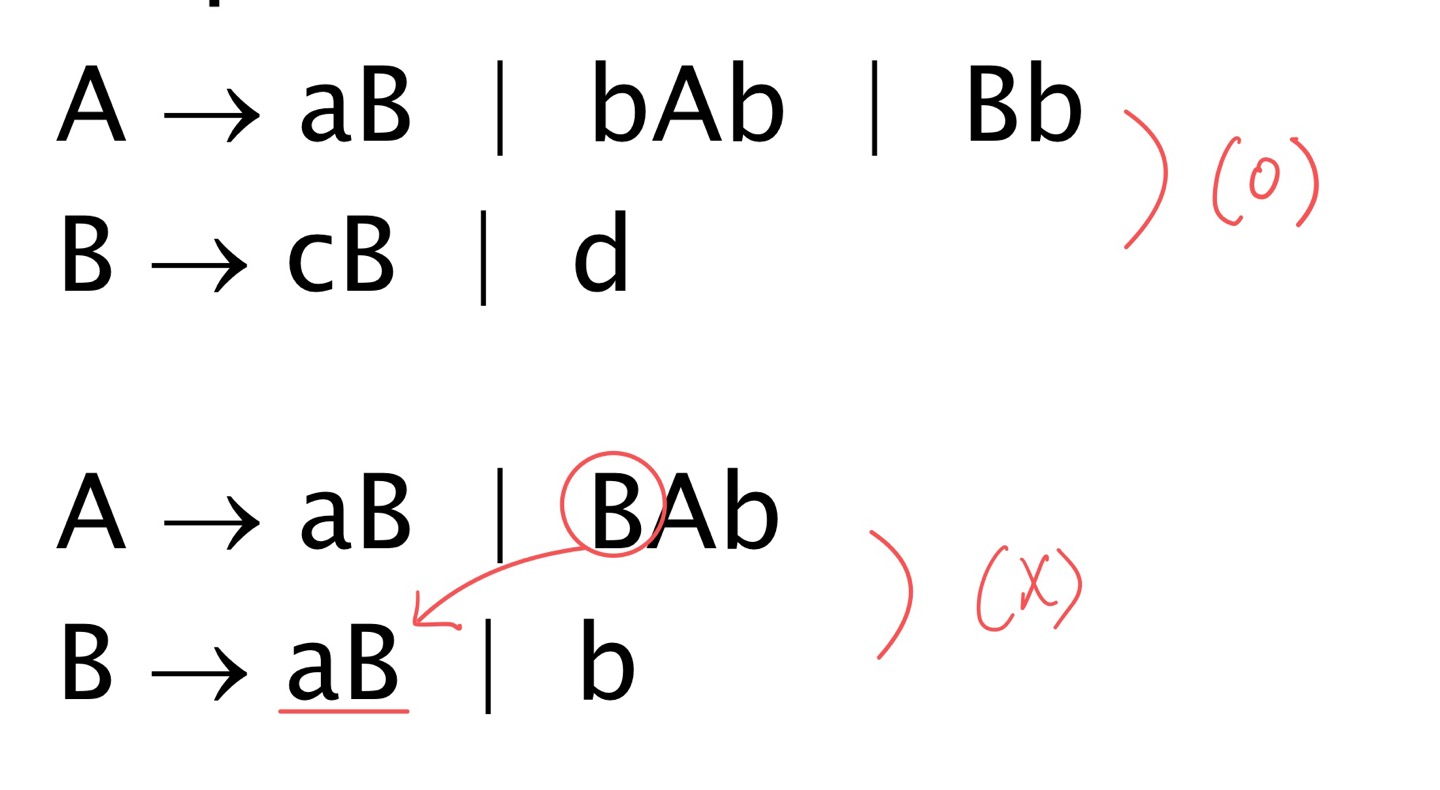
- Left factoring

※ Bottom-up Parser 개념 용어
- handle : rightmost의 역순으로 올 수 있는 nonterminal과 terminal의 조합
handle은 simple phrase에 해당한다. - phrase : 부분 parse tree의 모든 잎 노드들로 구성된 문자열(여러 번의 derivation)
- simple phrase : 단 한 번의 derivation을 통해서 만들어진 어구
바텀업 파싱은 handle pruning의 과정이라고 생각할 수 있다.
LR Parser
- parsing table, stack, input buffer로 이루어짐
- 효율적이고 거의 모든 문법에서 동작
- Shift-Reduce Algorithm을 사용
※ Shift-Reduce Algorithm의 Action Table 해석 방법
- Shift '숫자' : input에서 symbol을 하나 읽어서 stack에 저장한 후 state를 '숫자'로 변경
- Reduce '숫자' : '숫자'에 해당하는 rule에 따라 오른쪽 symbol을 왼쪽 symbol로 변경한 후, Goto Table로부터 state를 결정
- Accept : 에러 없이 파싱이 끝났음을 의미
- 빈칸 : 에러가 발생함을 의미
'PL' 카테고리의 다른 글
| [PL] Data types(1) (0) | 2022.04.18 |
|---|---|
| [PL] Names, Binding, Scope (0) | 2022.04.17 |
| [PL] Semantic의 표현 (0) | 2022.04.17 |
| [PL] Syntax의 표현 (0) | 2022.04.15 |
| [PL] 프로그래밍 언어 구현 방법 (0) | 2022.04.14 |