반응형
교차검증
교차검증이란 모델 학습 시 데이터를 훈련용과 검증용으로 교차하여 선택하는 방법이다.
교차검증을 사용하게 되면 모든 데이터를 학습 및 테스트에 활용하기 때문에 과적합 또는 과소 적합을 방지하고
더욱 일반화된 모델을 생성할 수 있게 된다.
교차검증을 위한 cross_val_score 메소드
sklearn은 교차검증을 위해 cross_val_score 메소드를 제공한다.
기본적인 파라매터로는 예측기 모델, 전체 X 데이터, 전체 y 데이터, 교차검증 개수를 넣어준다.
cv를 통해 교차검증 개수를 조정하고 scoring을 통해 교차검증 평가 방법을 수정할 수 있다.
수행 결과 교차검증 개수만큼의 예측기 객체가 생성되며 각 예측기의 평가 점수가 반환된다.
기본적으로 회귀 모델의 경우 R2 스코어, 분류 모델의 경우 정확도가 반환된다.
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
from sklearn.model_selection import cross_val_score
cv_scores = cross_val_score(model,
X_train_scaled,
y_train,
scoring='recall',
cv=5,
n_jobs=-1)
# 교차검증 결과의 확인 평가
print(f'(CV) scores : \n{cv_scores}')
print(f'(CV) scores mean : \n{cv_scores.mean()}')
# 머신러닝 모델의 학습
model.fit(X_train_scaled, y_train)
# 학습데이터에 대한 성능
score = model.score(X_train_scaled, y_train)
print(f'(MODEL) TRAIN SCORE : {score}')
# 테스트 데이터 셋에 대한 성능
score = model.score(X_test_scaled, y_test)
print(f'(MODEL) TEST SCORE : {score}')K-Fold Cross Validation
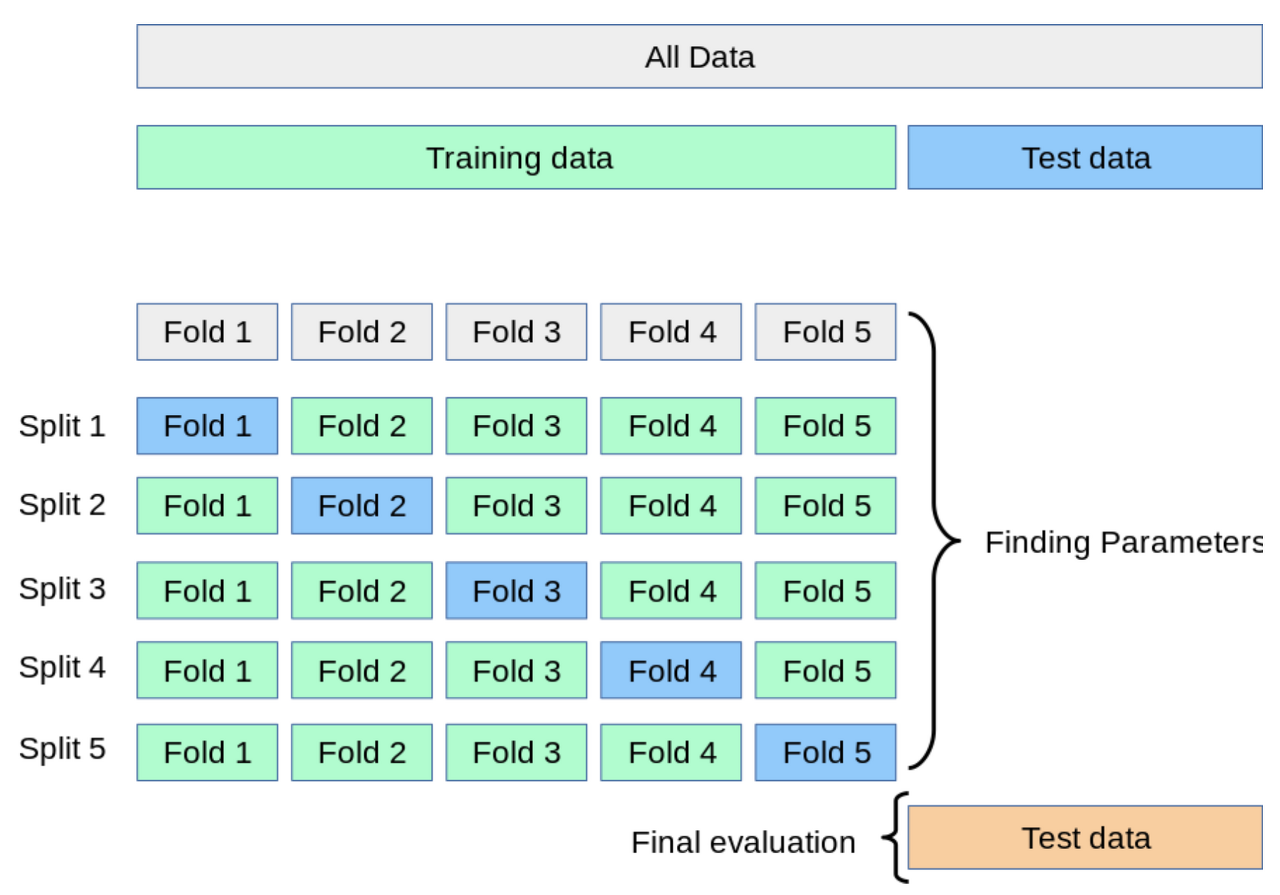
K-Fold는 가장 일반적으로 사용되는 교차검증 방법으로 전체 데이터셋을 K개의 fold로 나누어 1개는 test 데이터 셋으로,
나머지 K-1개는 train 데이터 셋으로 분할하는 과정을 반복함으로써 교차검증을 수행하는 방법이다.
K-Fold 교차검증 예제
KFold 클래스의 객체를 생성할 때는 n_splits 파라매터를 통해 분할할 fold의 개수를 정할 수 있고
shuffle=True로 해줌으로써 라벨이 정렬되어 있는 데이터를 균등한 비율로 섞어줄 수 있다.
이렇게 만들어준 KFold 객체를 cross_val_score 함수의 cv 매개변수에 사용하게 된다.
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
from sklearn.model_selection import KFold, cross_val_score
cv = KFold(n_splits=3, shuffle=True, random_state=1)
cv_scores = cross_val_score(
model, X, y,
cv=cv, scoring='accuracy', n_jobs=-1)
print(f'(CV) scores : \n{cv_scores}')
print(f'(CV) scores mean : \n{cv_scores.mean()}')
반응형
'머신러닝' 카테고리의 다른 글
| [머신러닝] Pipeline (0) | 2022.06.08 |
|---|---|
| [머신러닝] GridSearchCV (0) | 2022.06.08 |
| [머신러닝] 데이터 전처리 - 문자열 인코딩 (0) | 2022.06.07 |
| [머신러닝] 데이터 전처리 - 결측 데이터 처리 (0) | 2022.06.07 |
| [머신러닝] 선형 모델의 성능 향상을 위한 방법 (0) | 2022.04.22 |